目前最常见的运行大语言模型的方式是使用 Python 的transformers 库。只需要数行代码就可以加载并运行诸多 hugingface 平台上托管的语言模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from transformers import AutoTokenizerimport transformersimport torchmodel = "meta-llama/Llama-2-7b-chat-hf" tokenizer = AutoTokenizer.from_pretrained(model) pipeline = transformers.pipeline( "text-generation" , model=model, torch_dtype=torch.float16, device_map="auto" , ) sequences = pipeline( 'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?\n' , do_sample=True , top_k=10 , num_return_sequences=1 , eos_token_id=tokenizer.eos_token_id, max_length=200 , ) for seq in sequences: print (f"Result: {seq['generated_text' ]} " )
不过使用 transformers 库还是有一些先决条件的,包括:
配置 Python 虚拟环境;
安装 pytorch 库;
安装 cuda 环境等;
Mozilla 团队推出了一个新项目llamafile ,可以使用单个文件分发并运行大语言模型。
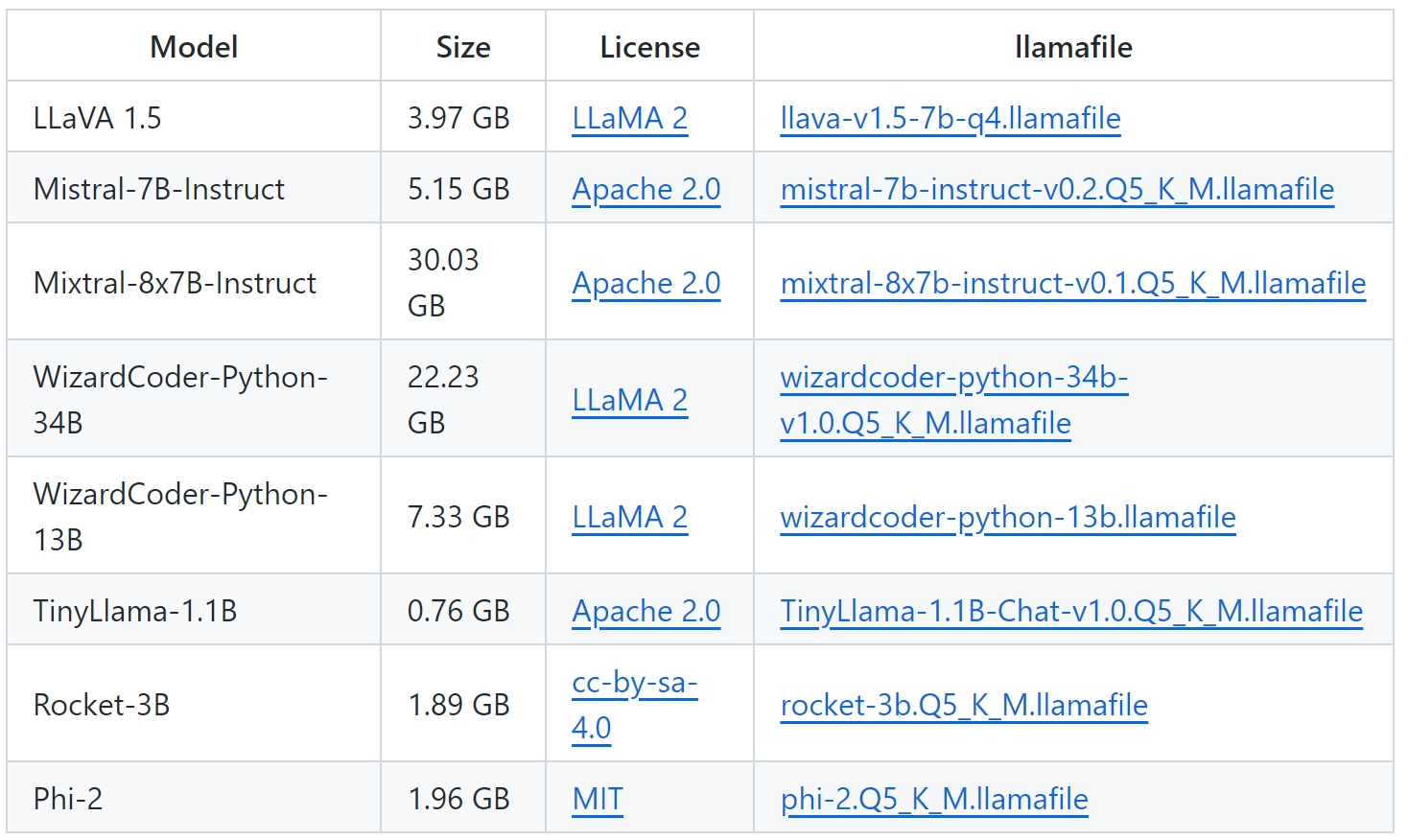
下载 llamafile 模型文件 llamafile项目的github主页上提供了若干个不同规模的语言模型的llamafile格式文件下载链接,我选择的是LLaVa 1.5,参数规模适中(3.97GB),能够运行在家里8G显存的PC上,并且本身是一个多模态模型,可以分析图片。
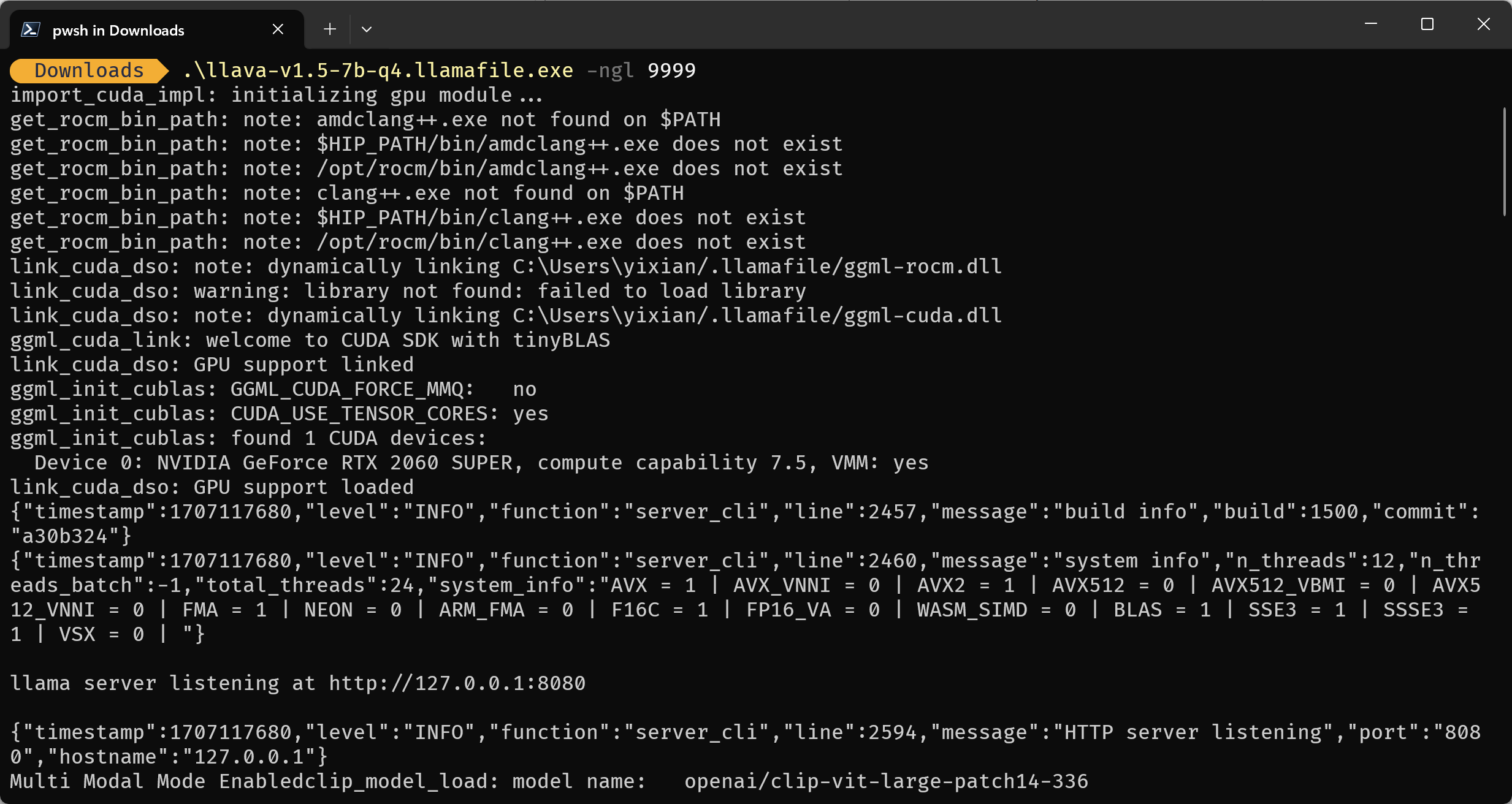
运行 llamafile Linux 平台 在 Linux平台上运行llamafile需要为文件添加可执行权限。
1 chmod +x llava-v1.5-7b-q4.llamafile
windows 平台 在windows平台上需要将llamafile的文件后缀改为.exe。
程序启动后会进行一些环境检测(例如是否有显卡或是否安装了cuda环境),检测完成后会输出模型参数配置,并自动启动web页面入口。
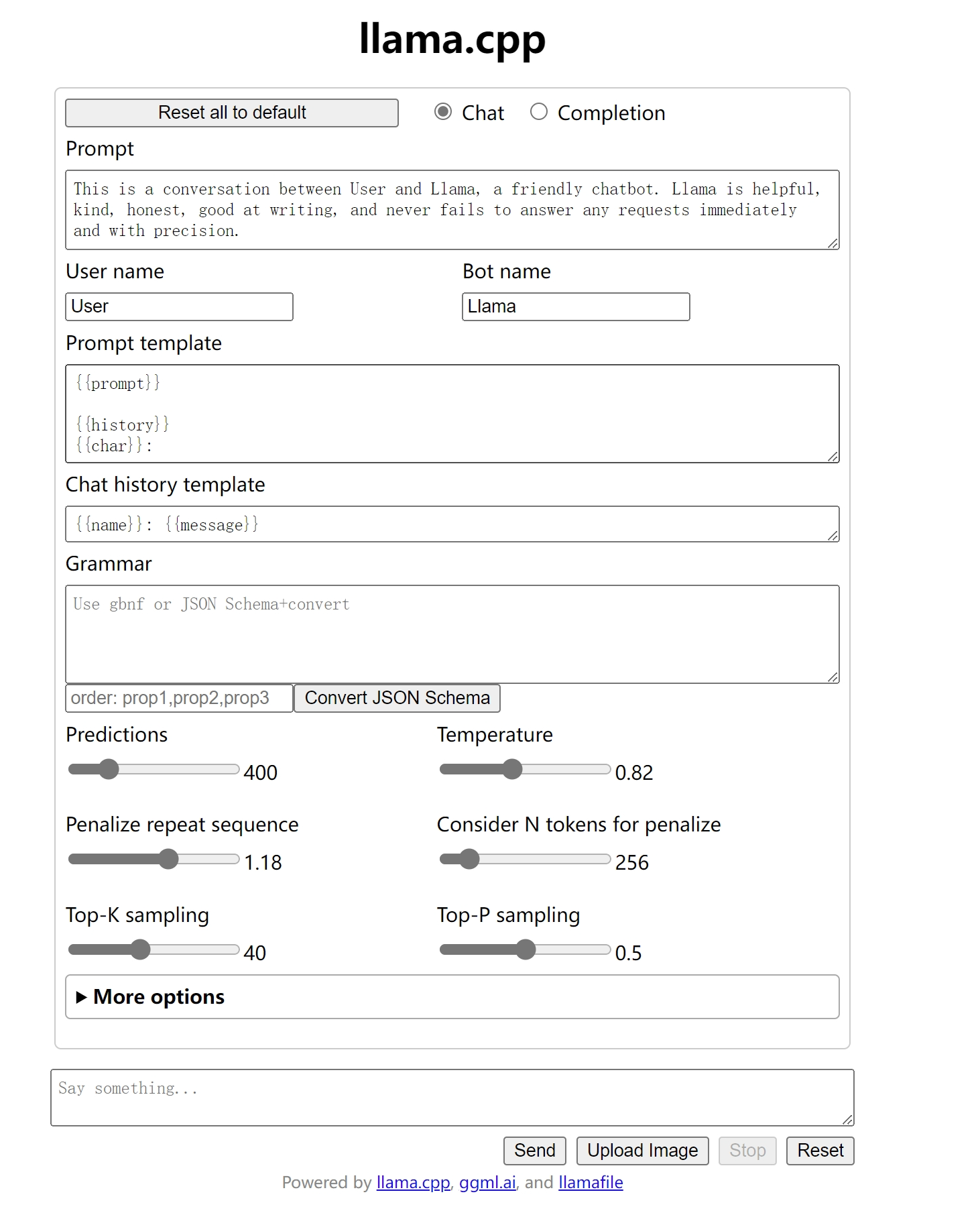
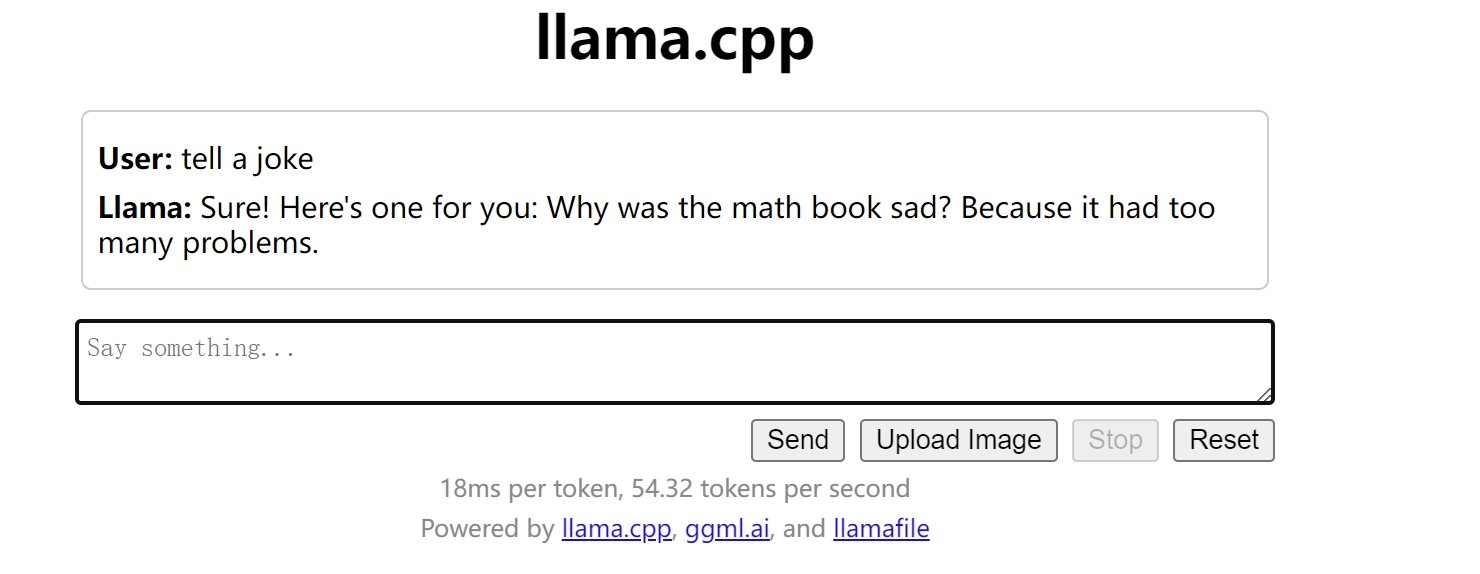
使用 Web UI 可以使用Web UI直接与大语言模型进行交互,包括对话模式和文本补全模式。
使用 sdk 也可以使用各个语言的openai sdk调用语言模型接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 import openaifrom openai import ChatCompletionopenai.api_base = "http://localhost:8080/v1" openai.api_key = "sk-1234" completion = ChatCompletion.create( model="LLaMA v2" , messages=[{"role" : "user" , "content" : "hello" }], ) message= completion.choices[0 ].message message.content
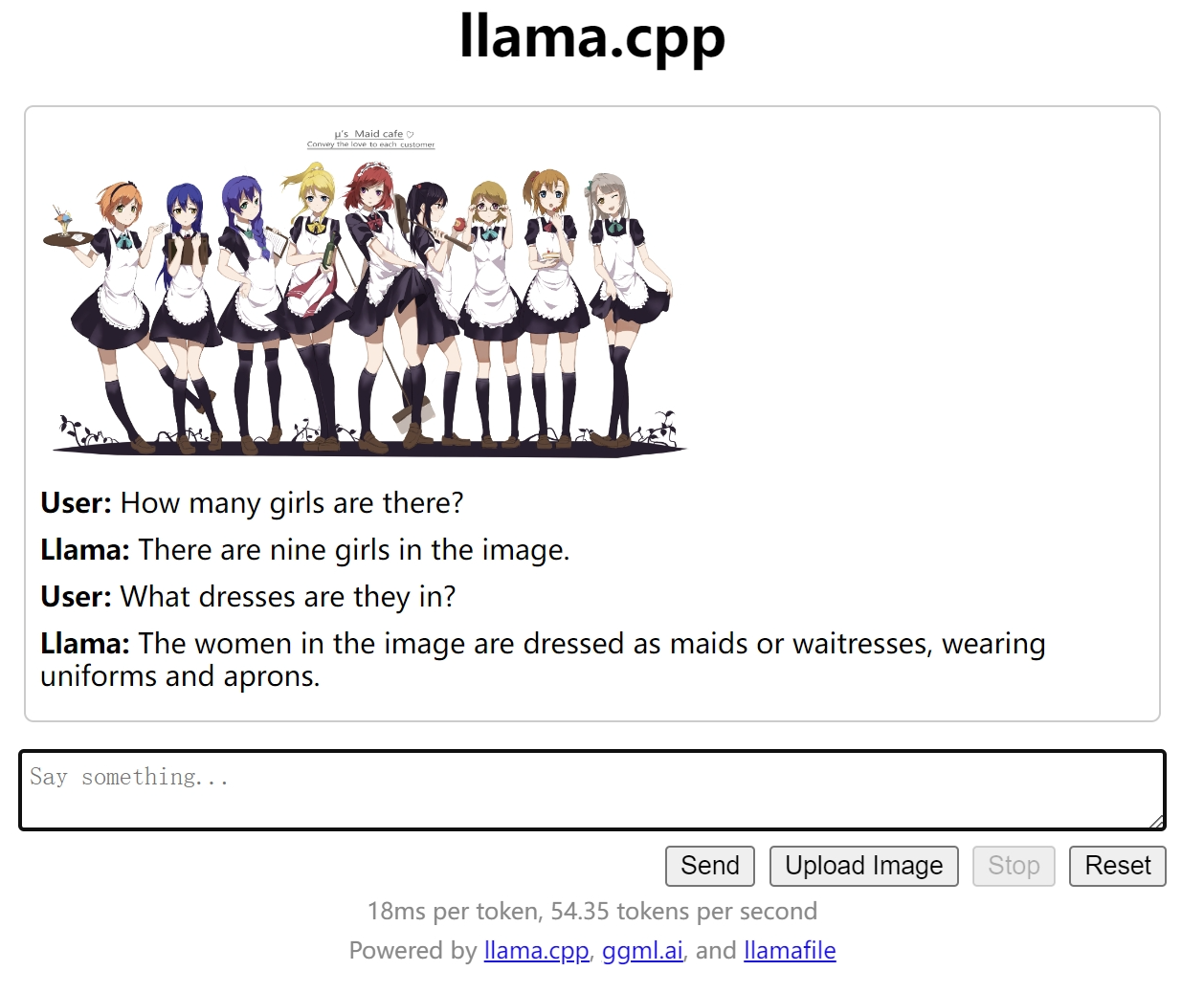
上传并使用图片 作为一个多模态模型,也可以上传图片并询问相关信息。
总结 llamafile格式不失为一个分发和运行大预言模型的好方法。